if的初始化语句
有个saveString函数,返回一个error值(如没有错误,返回nil),在main函数中,可以在处理它之前将返回值存储在一个err变量中:
func saveString(fileName string, str string) error {
err := ioutil.WriteFile(fileName, []byte(str), 0600)
return err
}
func main() {
err := saveString("hindi.txt", "Namaste") //调用saveString并存储返回值
if err != nil {
log.Fatal(err)
}
}
现在假设main中添加了另一个对saveString的调用,也使用了一个err变量,必须记住,在第一次使用err时使用一个短变量声明,以后更改为使用赋值,否则将得到一个编译错误。
func main() {
err := saveString("english.txt", "Hello") //使用了名为 err 的变量
if err != nil {
log.Fatal(err)
}
err := saveString("hindi.txt", "Namaste") //如果忘记将原始代码从短变量声明转换为赋值,将报错
if err != nil {
log.Fatal(err)
}
}
实际上,只是在if语句及其块中使用err变量,是否有一种方式可以限制变量的作用域,这样可以将每个事件当作一个单独的变量来处理呢?
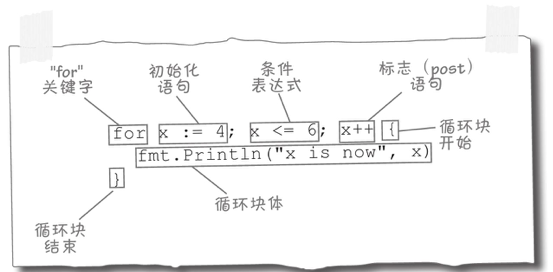
for循环它们可以包含一个初始化语句,可以在这里使用初始化变量,这些变量只在for循环块的作用域内。
与for循环类似,Go允许在if语句中的条件之前添加初始化语句,初始化语句通常用于初始化一个或多个变量,以便在if块中使用。
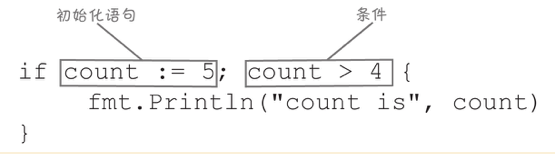
if count := 5, count > 4 {
fmt.Println("count is", count)
}
初始化语句中声明的变量的作用域仅限于if语句的条件表达式及其块。每个err变量被限制在if语句的条件和块中,将有两个独立的err变量,不用担心报错。
if err := saveString("english.txt", "Hello"); err != nil { //第一个err变量的作用域
log.Fatal(err)
}
if err := saveString("hindi.txt", "Namaste"); err != nil { //第二个err变量的作用域
log.Fatal(err)
}
这种对作用域的限制是双向的,如果一个函数有多个返回值,需要其中一个在if语句中,另一个在if语句外,那么可能无法在if初始化语句中调用它,会发现需要的在if块之外的值超出了作用域。
if number, err := strconv.ParseFloat("3.14", 64); err != nil {
log.Fatal(err)
}
fmt.Println(number * 2) //超出了作用域
相反,需要像往常一样在if语句前调用函数,这样它的返回值就在if语句的内部和外部的作用域之内:
number, err := strconv.ParseFloat("3.14", 64) //在if语句前声明变量
if err != nil { //仍在作用域内
log.Fatal(err)
}
fmt.Println(number * 2) //number 仍在作用域内
switch语句
当需要根据表达式的值执行几个操作之一时,可能会导致if语句和else子句的混乱,switch语句是表达这些选择的更有效的方式。
switch关键字,然后是条件表达式,再添加几个case表达式,每个case表达式都有一个条件表达式可能有的值,选择其值与条件表达式匹配的第一个case,并运行其所包含的代码,其他case表达式被忽略,还可以提供一个default语句,如果没有匹配的case,将运行该语句。
package main
import (
"fmt"
"math/rand"
"time"
)
func awardPrize() {
switch rand.Intn(3) + 1 { //条件表达式
case 1: //如果结果是1
fmt.Println("you win a cruise!") //打印这条消息
case 2:
fmt.Println("you win a car!")
case 3:
fmt.Println("you win a goat!")
default: //如果结果不是以上任何一个
panic("invalid door number") //那么产生panic
}
}
func main() {
rand.Seed(time.Now().Unix())
awardPrize()
}
问:其他语言,在每个case的末尾有个 break 语句,否则也会运行下一个case,Go不需要这样?
答:Go会在case代码末尾自动退出switch,如果希望下一个case代码也能运行,那么可以在一个case中使用fallthrough关键字。
switch case default fallthrough 这四个是结合使用的,表达式或类型说明符与switch中的case相比较从而决定执行哪一个。如果存在一个且最多只能存在一个 default 默认分支,所有的 case 分支都不满足时将执行 default 分支,且 default 分支不一定要放在最后的位置。Go switch 语句在执行完某个 case 子句后,不会再顺序地执行后面的 case 子句,而是结束当前 switch 语句。
使用 fallthrough 可以继续执行下一个 case 或 default 子句。case 表达式可以提供多个待匹配的值,使用逗号分隔。
switch { // 缺失的表达式为 true
case x < y: f1()
fallthrough // 强制执行下一个 case 子句
case x < z: f2()
// 此处没有 fallthrough,switch 执行流在此终止
case x == 4: f3()
}
switch tag {
default: s3() // default 子句可以出现在任意位置,不一定是最后一个
case 0, 1, 2, 3: s1() // case 表达式可以提供多个待匹配的值,使用逗号分隔
case 4, 5, 6, 7: s2()
}
switch x := f() { // 缺省表达式试为 true 且前面存在一条短变量申明语句
case x < 0: return -x // case 表达式无需为常量
default: return x
}
表达式选择可以没有表达式,缺省为true,这种写法也习惯的取代 if-else-if-else 语句链,表达式可以不是常量,表达式前面可以有简单语句,比如短变量声明语句。
类型选择:
类型选择比较类型而不是值,类似于表达式选择,由一个特殊的表达式表示类型,该表达式的形式是使用type的类型断言而不是实际类型。
switch x.(type) {
// case
}
使用实际类型T与表达式x的动态类型进行匹配,与类型断言一样,x必须是接口类型,列出的每个非接口类型T必须实现x且不能相同。
switch i := x.(type) {
case int:
printInt(i) // i 类型为 int
case float64:
printFloat64(i) // i 类型为 float64
case func(int) float64:
printFunction(i) // i 类型为 func(int) float64
case bool, string:
printString("type is bool or string") // i 类型为 bool or string
default:
printString("don't know the type") // i 类型未知
}
更多基本类型
| 类型 | 描述 |
|---|---|
| int int16 int32 int64 |
这些保存整数,与int一样,但是它们在内存中是特定的大小(类型名称中的数字以位为单位指定大小)。更少的位消耗更少的内存或其他存储,更多的位意味着可以存储更多的数字,应该使用int,除非有特定的理由使用其他的。 |
| uint | 像int一样,但它只包含无符号整数,不能包含负数。这意味着可以在相同的内存中放入更大的数字,只要确定这些值永远不会为负。 |
| uint8 uint16 uint32 uint64 |
它们包含无符号整数,与int一样,它们在内存中消耗特定数量的位 |
| float32 | float64类型保存浮点数并消耗64位内存,这是它较小的32位的表兄弟(浮点数没有8位或16位的变量) |
更多关于符文
rune
现代操作系统出现前,大多数计算都使用不带重音的英文字母来完成,共有26个字母(大小写),数量太少,一个字符可以用一个字节表示(还有1位可用),使用一种称为ASCII的标准来确保在不同的系统上将相同的字节值转换为相同的字母。
英文字母并不是唯一的书写系统;Unicode标准试图创建一组4字节的值,这些值可以表示这些不同书写系统中的每个字符(以及许多其他字符)。
Go使用rune类型的值来表示Unicode值,通常,一个符文代表一个字符。
rune是int32的类型别名,用于表示一个Unicode码点。
Go使用 UTF-8 ,这是一种表示Unicode字符的标准,每个字符使用1到4个字节,旧ASCII字符集中的字符仍然可以用一个字节表示,其他字符可能需要2到4个字节。
通常,无需担心字符如何存储的细节,也就是说,直到尝试将字符串转换为其组件字节并返回,例如,用两个字符串调用len函数,会得到不同结果:
asciiString := "ABCDE"
utf8String := "БГДЖИ"
fmt.Println(len(asciiString))
fmt.Println(len(utf8String))
输出:
5 //这个字符占用5个字节
10 //占用10个字节
当将字符串传递给len函数时,将返回以字节(而不是符文)为单位的长度,英文字母可以占用5个字节–每个符文只需1个字节,应为它来自旧的ASCII字符集,但是俄文需要10个字节–每个符文需要2个字节存储。
若需要字符串的字符长度,应该使用 unicode/utf8 包的 RuneCountInString 函数,此函数将返回正确的字符数,而不用考虑用于存储每个字符的字节数。
fmt.Println(utf8.RuneCountInString(asciiString))
fmt.Println(utf8.RuneCountInString(utf8String))
输出:
5 //这个字符串有5个符文
5 //这个字符串也有5个符文
安全地使用部分字符串意味着将字符串转换为符文,而不是字节。
Go支持将字符串转换为rune值的切片,并将符文切片转换回字符串,要使用部分字符串,应该将它们转换为rune值的切片,而不是byte值的切片,这样就不会意外抓取符文的部分字节。
asciiRunes := []rune(asciiString) //将字符串转换为符文切片
utf8Runes := []rune(utf8String) //将字符串转换为符文切片
asciiRunesPartial := asciiRunes[3:] //省略每个切片中的前3个符文
utf8RunesPartial := utf8Runes[3:] //省略每个切片中的前3个符文
fmt.Println(string(asciiRunesPartial))
fmt.Println(string(utf8RunesPartial)) //将这个符文切片转换成字符串
Go允许对字符串使用for…range循环,一次处理一个符文,而不是一个字节,这是一种更安全的方式。提供的第一个变量将被分配给字符串中的当前字节索引(而不是rune索引),第二个变量将被分配给当前的符文。
s := "Hello, 世界"
for _, r := range s {
fmt.Println("%c ", r)
}
Go的符文可以很容易处理部分字符串,而不必担心它们是否包含Unicode字符。
任何时候想要处理字符串的一部分,就把它转换成符文,而不是字节!
有缓冲的channel
Go有两种channel:有缓冲的和无缓冲的。
当goroutine在无缓冲的channel上发送值时,会立即阻塞,直到另一个goroutine接收到该值。
有缓冲的channel可以在导致发送的goroutine阻塞之前保存一定数量的值。
在创建channel时,可以通过给make传递第二个参数来创建有缓冲的channel,该参数包含channel应该能够在其缓冲区中保存的值的数量。

channel := make(chan string, 3) //“3”此参数指定channel缓冲区的大小
当goroutine通过channel发送一个值时,该值被添加到缓冲区中,发送的goroutine将继续运行,而不被阻塞。
channel <- "a"

发送的goroutine可以继续在channel上发送值,直到缓冲区被填满,只有这时,额外的发送操作才会导致goroutine阻塞。
channel <- "b"
channel <- "c"
channel <- "d"

当另一个goroutine从channel接收一个值时,它从缓冲区提取最早添加的值。

额外的接收操作将继续清空缓冲区,而额外的发送操作将填充缓冲区。

例:
用一个无缓冲的channel运行一个程序,然后更新为带缓冲的channel,比较区别。
package main
import (
"fmt"
"time"
)
func sendLetters(channel chan string) {
time.Sleep(1 * time.Second) //发送4个值,每个值前休眠1秒
channel <- "a"
time.Sleep(1 * time.Second)
channel <- "b"
time.Sleep(1 * time.Second)
channel <- "c"
time.Sleep(1 * time.Second)
channel <- "d"
}
func main() {
fmt.Println(time.Now()) //打印程序开始的时间
channel := make(chan string) //创建一个无缓冲的channel
go sendLetters(channel) //在新的goroutine上启动sendLetters
time.Sleep(5 * time.Second) //主goroutine休眠5秒
fmt.Println(<-channel, time.Now()) //接收并打印4个值以及当前的时间
fmt.Println(<-channel, time.Now())
fmt.Println(<-channel, time.Now())
fmt.Println(<-channel, time.Now())
fmt.Println(time.Now()) //打印程序结束的时间
}
输出:
2023-08-23 15:12:28.402341 +0800 CST m=+0.000126414
a 2023-08-23 15:12:33.403655 +0800 CST m=+5.001530631 //当主goroutine醒来时,第一个值已经在等待接收
b 2023-08-23 15:12:34.404896 +0800 CST m=+6.002790206 //但sendLetters goroutine在收到第一个值前一直被阻塞,所以必须等待后面的值发送出去
c 2023-08-23 15:12:35.405858 +0800 CST m=+7.003769905
d 2023-08-23 15:12:36.406175 +0800 CST m=+8.004105594
2023-08-23 15:12:36.406232 +0800 CST m=+8.004162602 //程序运行花费8s
当main goroutine醒来时,从channel接收4个值,但sendLetters goroutine被阻塞了,等待main接收第一个值,因此,当sendLetters goroutine恢复时,main goroutine必须在每个剩余值之间等待1秒。
更新为带缓冲的channel:
func main() {
channel := make(chan string, 1) //创建一个有缓冲的channel,在阻塞前可以保存一个值
// ...
}
当sendLetter将它的第一个值发送到channel时,不会阻塞,直到主goroutine接收到它,所发送的值将进入channel的缓冲区,只有当第二个值被发送(但还没有任何值被接收)时,channel的缓冲区才会被填满,sendLetters goroutine才会被阻塞,向channel中添加一个单值缓冲区可减少1秒的时间。
func main() {
channel := make(chan string, 3) //创建一个有缓冲的channel,在阻塞前可以保存三个值
// ...
}
将缓冲区大小增加到3,这允许sendLetters在不阻塞的情况下发送三个值,在最后一次发送时阻塞,但这是在它的所有1秒Sleep调用完成之后,因此,当主goroutine在5秒后醒来时,它立即接收到在有缓冲channel中等待的三个值,以及导致sendLetters阻塞的值。这让程序只需5秒完成。
